图与网络模型及方法
图与网络模型及方法
图
基本背景
图论起源于 18 世纪。第一篇图论论文是瑞上数学家欧拉于 1736 年发表的
“哥尼斯堡的七座桥”
哥尼斯堡有七座桥将普莱格尔河中的两个岛及岛与河岸联结起来,问题是要从这四块陆地中的任何一块开始通过每一座桥正好一次,再回到起点。
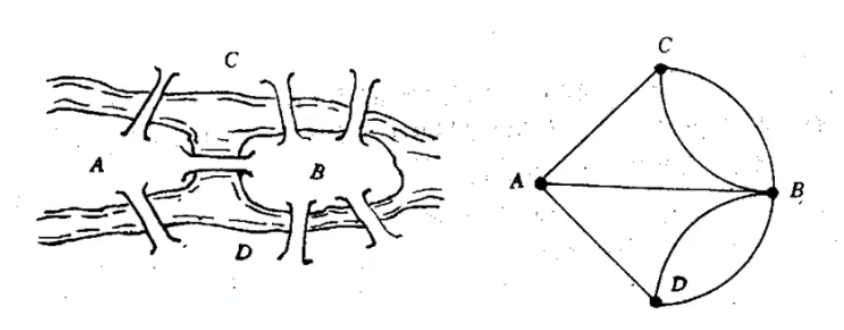
欧拉:七桥问题无解
无法“一笔画”,因为都是奇数点
1847年,克希霍夫为了给出电网络方程而引进了“树”的概念。1857 年,凯莱在计数烷 C n H,,的同分异构物时,也发现了“树”。哈密尔顿于 1859 年提出“周游世界”游戏,用图论的术语,就是如何找出一个连通图中的生成圈近几十年来,由于计算机技术和科学的飞速发展,大大
地促进了图论研究和应用,图论的理论和方法已经渗透
到物理、化学、通讯科学、建筑学、运筹学、生物遗传
学、心理学、经济学、社会学等学科中。
图论中所谓的“图”是指某类具体事物和这些事物之间的联系。如果我们用点表示这些具体事物,用连接两点的线段 (直的或曲的) 表示两个事物的特定的联系,就得到了描述这个“图”的几何形象。图论为任何一个包合了一种二元关系的离散系统提供了一个数学模型,借助于图论的概念、理论和方法,可以对该模型求解。哥尼斯堡七桥问题就是一个典型的例子
基本概念
图 项点集 边集
所谓的图,直观地讲就是在平面上n个点,把其中的些点对用曲线或直线连接起来,不考虑点的位置与连线曲直长短,这样形成一个关系结构就是一个图。记成G=(V,E),V是以上述点为元素的顶点集,E是以上述连线为元素的边集。
G graph; V vertex; E edge
有向图 无向图 混合图
如果各条边都加上方向,则称为 有向图 ,否则称为 无向图 。如果有的边有方向,有的边无方向,则称为 混合图 。
简单图 完全图 非完全图
如果任两顶点间最多有一条边,且每条边的两个端点皆不重合的图,称为 简单图
如果图的两顶点间有边相连,则称此两顶点 相邻 .每一对顶点都相邻的图称为 完全图 ,否则称为 非完全图 ,完全图记为K|n|。
二分图 完全二分图
若V=X $\bigcup$ Y,X $\bigcap$ Y=重,|X|·|Y|≠ 0(这里|X|表示顶点集X中元素的个数),且X中无相邻的顶点对,Y中亦然,则称图G为二分图;特别地,若对任意u∈X,u与Y中每个顶点相邻,则称图G为完全二分图,记为K|X|,|Y|。
顶点的度 奇顶点 偶顶点
设v∈V是边e ∈ E的端点,则称y与e相关联,与顶点v关联的边数称为该顶点的度,记为d(v),度为奇数的顶点称为奇顶点,度为偶数的顶点称为偶顶点。可以证明$\sum_{v∈V(G)}$ d(v)=2|E|,即所有顶点的度数之和是边数的两倍且由此可知奇顶点的总数是偶数(d-degree)
轨道 回路 圈 连通图
设w=v0e1v1e2···ekvk,其中ei∈E,1≤i≤k,vj∈V,0≤j≤k,ei与v-和vi-1关联,称W是图G的一条道路,k为路长,v0为起点,vk为终点; 各边相异的道路称为迹:各顶点相异的道路称为轨道。若W是一轨道,可记为P(v0,vk);起点与终点重合的道路称为回路;起点与终点重合的轨道称为圈,即对轨道P(v0,vk),当v0=vk时成为一圈;图中任两顶点之间都存在道路的图,称为连通图。图中含有所有顶点的轨道称为* Hamilton 轨,闭的 Hamilton 轨称为 Hamilton 圈;含有 Hamilton 圈的图称为 Hamilton 图*。
称两顶点u,v分别为起点和终点的最短轨道之长为顶点u,v的距离;在完全二分图K|X|,|Y|中,X中两顶点之间的距离为偶数,X中的顶点与Y中的顶点的距离为奇数。
赋权图
赋权图是指每条边都有一个(或多个)实数对应的图这个(些)实数称为这条边的权(每条边可以具有多个权)
赋权图在实际问题中非常有用。根据不同的实际情况,权数的含义可以各不相同。例如,可用权数代表两地之间的实际距离或行车时间,也可用权数代表某工序所男的加工时间等。
邻接矩阵表示法
邻接矩阵是表示顶点之间相邻关系的矩阵
邻接矩阵记作W=(wij)n*n
当G为赋权图时
$$ W_{ij}=\left{
\begin{array}{rcl}
权值 & & {当v_i与v_j之间有边时}\
0或∞ & & {当v_i与v_j之间无边时}
\end{array} \right. $$
当G为非赋权图时
$$ W_{ij}=\left{
\begin{array}{rcl}
0 & & {当v_i与v_j之间有边时}\
1 & & {当v_i与v_j之间无边时}
\end{array} \right. $$

稀疏矩阵表示法
稀疏矩阵是指矩陈中零元素很多,非零元素很少的矩阵对于稀疏矩阵,只要存放非零元素的行标、列标、非零元素的值即可,可以按如下方式存儒(非零元素的行地址,非零元素的列地址),非零元素的值

(1)令I(u0)=0,对v≠u0,令l(v) = ∞, S0 ={u0},i=0
(2)对每个v属于$\overline{S_i}$ ($\overline{S_i}$ =V\Si),用$\mathop{\min}\limits_{u∈S_i}${l(v),l(u)+w(uv)}代替l(v),这里w(uv)表示顶点u和v之间边的权值。计算把达到这个最小值的一个顶点记为ui+1,令 Si+1=S i $\cup$ {ui+1}.
(3) 若i=|V|-1,停止;若i<|V|-1,用i+1代替i,转(2).
算法结束时,从u0到各顶点v的距离由v的最后一次标号I(v)给出。在v进入Si之前的标号I(v)叫 T 标号,进入Si时的标号I(v)叫P标号。
例
某公司在六个城市c1,c2,···,c6,中有分公司,从ci到cj的直接航程票价记在下述矩阵的(i,j)位置上(∞表示无直接航路),请帮助该公司设计一张城市c1到其他城市间的票价最便宜的路线图
$$
\begin{bmatrix}
0 & 50 & ∞ & 40 & 25 & 10 \
50 & 0 & 15 & 20 & ∞ & 25 \
∞ & 15 & 0 & 10 & 20 & ∞ \
40& 20 & 10 & 0 & 10 & 25 \
25 & ∞ & 20 & 10 & 0 & 55 \
10 & 25 & ∞ & 25 & 55 & 0
\end{bmatrix}
$$
用矩阵 an*n (n为顶点个数)存放各边权的邻接矩阵,行向量pb、index1、index2,、d分别用来存放P标号信息标号顶点顺序、标号顶点索引、最短通路的值。其中分量
$$ pb_{(i)}=\left{
\begin{array}{rcl}
1 & & {当第i顶点的标号已成为P标号}\
0 & & {当第i顶点的标号未成为P标号}
\end{array} \right. $$
index2(i) 存放始点到第i顶点最短通路中第i顶点前
顶点的序号;
d(i) 存放由始点到第i项点最短通路的值.
求得c1到c2,···,c6的最便宜票价分别为35,45,35,25,10。
两个指定顶点之间最短路问题的数学规划模型
假设有向图有n个顶点,现需要求从顶点v1到顶点vn的最短路。设W =(wij)n*n为邻接矩阵,其分量为
$$ w_{ij}=\left{
\begin{array}{rcl}
边v_iv_j的权值& & {v_iv_j∈E}\
∞ & & {其他}
\end{array} \right. $$
决策变量为xij,当xij =1,说明弧vivj位于顶点至顶点vn的最短路上;否则 xij = 0。
其数学规划表达式为
${min}\sum_{v_iv_j∈E}{w_{ij}x_{ij}}$
$$ {s.t.}\sum^n_{j=1,v_iv_j∈E}{x_{ij}}-\sum^n_{j=1,v_iv_j∈E}{x_{ij}}=\left{
\begin{array}{rcl}
1 & & {i = 1}\
-1 & & {i = n}\
0 & & {i≠1,n}
\end{array} \tag{$x_{ij}$=0或1} \right. $$
有向
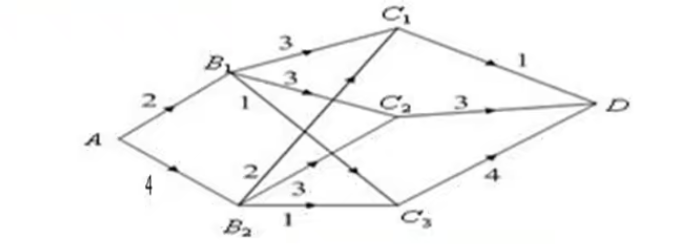
有向图的最短路问题
在下图中,用点表示城市,现有A,B1,B2,C1,C2,C,3,D共 7 个城市。点与点之间的连线表示城市间有道路相连。连线旁的数字表示道路的长度现计划从城市4到城市D铺设一条天然气管道,请设计出最小长度管道铺设方案。
1 | model: |
无向
无向图的最短路问题
下图中的最短路。
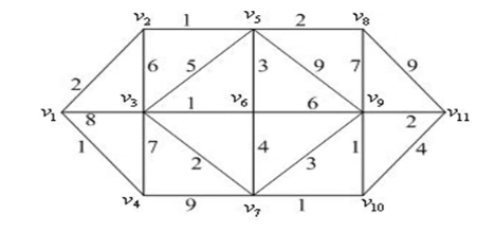
分析 上一例处理的问题属于有向图的最短路问题,本例是处理无向图的最短路问题,在处理方式上与有向图的最短路问题有一些差别,这里选择赋权邻接矩阵的方法编写LINGO程序。
1 | model: |
与有向图相比较,在程序中只增加了一个语句@sum(cities(j):x(j,1))=0,即
从顶点 1 离开后,再不能回到该顶点。
求得的最短路径为 1→2→5→6→3→7→10→9→11,最短路径长度为 13。
Floyd算法
思路
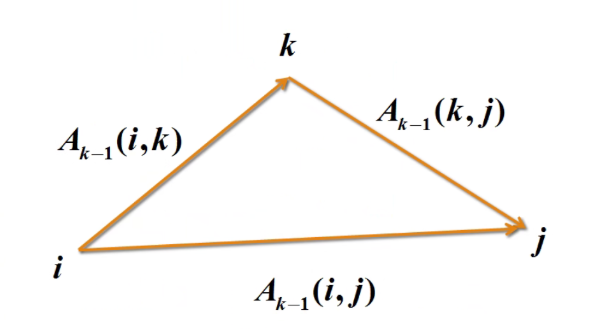
Ak(i,j)= min(Ak-1(i,j),Ak-1(i,k)+Ak-1(k,j))
详解

Floyd 算法的基本思想是递推产生一个矩阵序$A_1,···,A_k,···,A_n$,其中矩阵$A_k$,的第i行第j列元素$A_k(i,j)$表示从顶点vi到顶点vj;的路径上所经过的顶点序号不大于的最短路径长度。
计算时用迭代公式
$A_k(i,j)= min(A_{k-1}(i,j),A_{k-1}(i,k)+A_{k-1}(k,j))$
k是迭代次数,i,j,k =1,2,…,n。
最后,当 k=n 时,An即是各顶点之间的最短通路值。
练习
某出版社准备在某市两个区建立两个销售代理点向大学生售书,每个区大学生数量如图,每个销售代理点只能向本区和一个相邻区的大学生售书,问两个代理点建立在何处,才能使供应量最大?试建立图论模型求解。

最小生成树问题
基本概念
连通的无圈图叫做树,记之为T;其度为 1 的顶点称为叶子顶点;显然有边的树至少有两个叶子顶点。
若图 G=(V(G),E(G)) 和树 T=(V(T),E(T)) 满足V(G)=V(T),E(T) C E(G),则称T是G的生成树。图G连通的充分必要条件为G有生成树,一个连通图的生成树的个数很多。
树有下面常用的五个要条件
(1) G=(V,E)是树当且仅当G中任二顶点之间有且仅有一条轨道
(2) G是树当且仅当G无圈,且 |E|=|V|-1。
(3) G是树当且仅当G连通,且 |E| =|V|-1。
(4) G是树当且仅当G连通,且 $\forall$ e ∈|E|,G - e 不连通。
(5) G是树当且仅当G无圈, $\forall$e $\notin $E,G+e恰有一个圈。
欲修筑连接n个城市的铁路,已知i城与j城之间的铁路造价为$c_{ij}$,设计一个线路图,使总造价最低
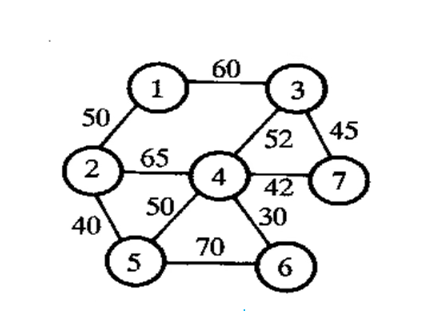
prim 算法构造最小生成树
构造连通赋权图G=(V,E,W)的最小生成树,设置两个集合P和Q,其中P用于存放G的最小生成树中的顶点集合Q存放G的最小生成树中的边。今集合P的初值为P ={$v_1$}(假设构造最小生成树时,从顶点”出发),集合Q的初值为Q=$\phi$(空集)。prim 算法的思想是,从所有p ∈ Pv∈V-P的边中,选取具有最小权值的边 pv,将顶点v加入集合P中,将边pv加入集合Q中,如此不断重复,直到P=V时,最小生成树构造完毕,这时集合Q中包合了最小生成树的所有边。
用 prim 算法求下图的最小生成树。
Kruskal 算法构造最小生成树
科斯克尔(Kruskal) 算法是一个好算法.Kruskal算法如下
(1) 选e $\in$ E(G),使得$e_1$是权值最小的边。(w($e_1$)=min)
(2)若$e_1;e_2,···,e_i$已选好,则从E(G)-{$e_1,e_2,···,e_i$}中选取$e_{i+1}$,使得
- i) G[{$e_1,e_2,···,e_i,e_{i+1}$}]无圈,且
- ii) w($e_{i+i}$)是E(G)-e,,e}中权值最小的边(w($e_{i+i}$)=min)
(3) 直到选得$e_{v-1}$为止。
Kruskal算法构造上一例的最小生成树
用$index_{2*n}$存放各边端点的信息,当选中某一边之后就将此边对应的顶点序号中较大序号u改为此边的另一序号v,同时把后面边中所有序号为u的改为v。
此方法的几何意义是:将序号u的这个顶点收缩到v顶点,u顶点不复存在。后面继续寻查时,发现某边的两个预点序号相同时认为已被收缩掉,失去了被选取的资格.
求解结果和例4.5相同。
1 | clc;clear; |
网络最大流问题
这里我的笔记不全了原因如下
- 本来作的笔记因为笔记本突然死机,重启之后就丢失了
- 最大流这里以前没有学过,边听可边做笔记就过于慢了
网上找到了别人的一些笔记博客,直接放链接在这里 最大流(网络流基础概念+三个算法)
基本概念与基本定理
网络与流
给一个有向图D=(V,4),其中A为弧集在V中指定了一点,称为发点 (记为$v_s$),和另一点,称为收点 (记为$v_t$),其余的点叫中间点,对于每一条弧($v_i$,$v_j$)$\in$A,对应有一个c($v_i$,$v_j$)$\ge$0 (或简写为$c_{ij}$),称为弧的容量。通常我们就把这样的有向图D叫作一个网络.
记作D=(V,A),其中C=c{$c_{ij}$}.
所谓网络上的流,是指定义在弧集合4上的一个函
数f=_fa=ff(,并称f为弧(,y)上的流量。
最小费用最大流问题
最小费用最大流
给定网络D=(V,A,C),每一弧($v_i$,$v_j$)$\in$A上,除了已给容量$c_{ij}$外,还给了一个单位流量的费用b($v_i$,$v_j$)$\ge$0(简记为$b_{ij}$)。所谓最小费用最大流问题就是要求一个从发点”,到
收点”,的最大流,使流的总输送费用 $\sum_{(v_i,v_j)\in A}b_{ij}f_{ij}$取最小值
最小费用最大流问题可以归结为两个线性规划问题,首先用(4.1) 的线性规划模型求出最大流量$v_{(f_max)}$,然后用如下的线性规划模型求出最大流对应的最小费用
$$min\sum_{(v_i,v_j)\in A}b_{ij}f_{ij}$$
$$s.t. 0\ge f_{ij}\ge c_{ij},\forall (v_i,v_j) \in A$$
$$ \sum_{j:(v_i,v_j)\in A}f_{ij} - \sum_{j:(v_j,v_i)\in A} = d_i$$
其中
$$ d_i=\left{
\begin{array}{rcl}
v_{(f_{max})} & & {i=s}\
-v_{(f_{max})} & & {i=t}\
0 & & {i≠s,t}
\end{array} \right. $$
这里v($f_{max}$)表示(4.1)线性规划模型求得的最大流的流量。
当我们使用滚动平均值时,我们会计算一系列数据的平均值,但只考虑最近的一部分数据。在每一步中,我们将最新的数据加入计算,并从计算中移除最旧的数据,从而保持数据窗口的大小不变。这样做的好处是可以平滑数据,减少噪音和异常值的影响,并更好地反映数据的长期趋势。
滚动平均的数学公式如下:
设有一列数据 $x_1, x_2, x_3, \ldots, x_n$,滚动平均的窗口大小为 $k$。
在滚动平均的初始阶段,我们先计算前 $k$ 个数据的平均值,表示为 $m_1$:
$$m_1 = \frac{1}{k} \sum_{i=1}^{k} x_i$$
然后,随着数据的逐步增加,我们更新滚动平均值的计算。在第 $i$ 步,我们将新数据 $x_i$ 加入滚动窗口,并从计算中移除最旧的数据 $x_{i-k}$,更新滚动平均值 $m_i$ 如下:
$$m_i = m_{i-1} + \frac{1}{k} (x_i - x_{i-k})$$
在这个公式中,$m_{i-1}$ 表示第 $i-1$ 步的滚动平均值,$x_i$ 表示新加入的数据,$x_{i-k}$ 表示移除的最旧数据。
通过这种方式,滚动平均可以动态地保持数据窗口大小,对数据进行平滑处理,同时在计算过程中不需要保留所有数据,只需要保存上一步的滚动平均值和相关的数据。
滚动平均常用于时间序列数据的平滑处理,例如股票价格的移动平均线就是一种常见的滚动平均应用。在处理具有较大波动或不连贯性的数据时,滚动平均可以提供更稳定和可靠的结果,减少异常值的影响,帮助我们更好地分析数据的趋势和变化。
当处理时间序列数据时,我们经常会遇到一些具有周期性或趋势性的数据。滞后期平滑和指数加权移动平均是两种常见的平滑方法,用于去除数据中的噪音和突发变化,从而更好地反映数据的长期趋势。
- 滞后期平滑(Lag Smoothing):
滞后期平滑是一种简单的平滑方法,它通过将当前数据点与之前的数据点进行平均来生成平滑后的数据。滞后期平滑的数学公式如下:
设有一列数据 $x_1, x_2, x_3, \ldots, x_n$,滞后期平滑的滞后期数为 $p$。
在滞后期平滑中,第 $i$ 个平滑后的数据点 $y_i$ 是前 $p$ 个原始数据点 $x_{i-p}, x_{i-p+1}, \ldots, x_{i-1}, x_i$ 的平均值,即:
$$y_i = \frac{1}{p} \sum_{j=1}^{p} x_{i-j}$$
滞后期平滑的主要优点是简单易懂,易于计算。它可以一定程度上平滑数据,去除一些短期内的波动,但对于长期趋势的反映较差。
- 指数加权移动平均(Exponential Moving Average,EMA):
指数加权移动平均是一种对最近的数据点进行加权的平滑方法,它给予较新的数据点较大的权重,较旧的数据点较小的权重。指数加权移动平均的数学公式如下:
设有一列数据 $x_1, x_2, x_3, \ldots, x_n$,指数加权移动平均的平滑因子为 $\alpha$(通常取一个接近于1的值,如0.1、0.3等)。
在指数加权移动平均中,第 $i$ 个平滑后的数据点 $y_i$ 由以下公式计算得出:
$$y_i = \alpha \cdot x_i + (1 - \alpha) \cdot y_{i-1}$$
其中,$y_{i-1}$ 表示第 $i-1$ 个平滑后的数据点。指数加权移动平均对最近的数据点赋予较大的权重,随着数据点的逐渐远离,权重逐渐减小,因此能够更好地反映数据的短期变化。
指数加权移动平均通常用于平滑数据并提取长期趋势。与滞后期平滑相比,指数加权移动平均对数据的响应更加敏感,可以更好地捕捉数据中的变化,但在数据中存在较多噪音或异常值时,可能会受到这些值的影响。
总体而言,滞后期平滑和指数加权移动平均都是常见的平滑方法,可以根据数据的特点和需要选择合适的方法来处理时间序列数据,从而更好地分析数据的趋势和规律。
可行流与最大流
满足下列条件的流称为可行流
(1) 容量限制条件: 对每一弧(v;,;)e ,c
(2)平衡条件
对于中间点,流出量=流入量,即对于每个i(i≠s,t)有
$$\sum_{j:(v_i,v_j)\in A}f_{ij}- \sum_{j:(v_i,v_j)\in A}f_{ji}=0$$对于发点$v_s$,记
$$\sum_{(v_s,v_j)\in A}f_{sj}- \sum_{j:(v_j,v_s)\in A}f_{js}=v_{(f)}$$对于收点$v_t$,
fi =-wf),
$$\sum_{(v_t,v_j)\in A}f_{sj}- \sum_{j:(v_j,v_t)\in A}f_{js}=-v_{(f)}$$
wV
式中”/)称为这个可行流的流量,即发点的净输出量。
可行流总是存在的,例如零流。
最大流问题可以写为如下的线性规划模型
$$\max v_{(f)}$$
$$
$$
增广路
若给一个可行流f={$f_{ij}$},把网络中使$f_{ij}=c_{ij}$的弧称为饱和弧,使$f_{ij} < c_{ij}$的弧称为非饱和弧。把$f_{ij}=0 $的弧称为零流弧,$f_{ij}>0 $的弧称为非零流弧。
若从是网络中联结发点$v_s$和收点$v_t$的一条路,我们定义路的方向是从$v_s$到$v_t$,则路上的弧被分为两类:一类是弧的方向与路的方向一致,叫做前向弧。前向弧的全体记为$\mu^*$。另一类弧与路的方向相反,称为后向弧。后向弧的全体记为$\mu^-$。
设f是一个可行流,$\mu$是从$v_s$到$v_t$的一条路,若$\mu$满足: 前向弧是非饱和弧,后向弧是非零流弧,则称u为 (关于可行流f) 一条增广路。
寻求最大流的标号法(Ford-Fulkerson)
从$v_s$到$v_t$,的一个可行流出发 (若网络中没有给定f,则可以设f是零流),经过标号过程与调整过程,即可求
得从”到”的最大流。
这种方法分为以下两个过程:
- A.标号过程:通过标号过程寻找一条可增广轨。
- B.增流过程:沿着可增广轨增加网络的流量。
这两个过程的步骤分述如下
- (A) 标号过程:在下面的算法中,每个顶点”的标号值有两个,”的第一个标号值表示在可能的增广路上,”的前驱顶点;”的第二个标号值记为6.,表示在可能的增广路上可以调整的流量。
- (1)初始化,给发点$v_s$标号为(0,∞)
- (2)若顶点$v_x$已经标号,则对$v_x$的所有未标号的邻接结点$v_y$按一下规则标号
- (i)若$(v_x,x_y)$且$ f_{xy}<c_{xy}$时,令$\delta_y=min${$c_{xy}-f_{xy}$}则给顶点$v_y$标号为($v_x,\delta_y$),若$f_{xy}=c_xy}$则不给顶点,标号i)(v,)EA,且/>0,令=minf3,则给标号为(-”,,这里第一个号值,表示在可能的增路上,(v;’)为反向弧;若/=0,则不给标号。
- (ii)
- (3)不断地重复步骤(2)直到收点$x_t$被标号或不再有顶点可以标号为止。当”被标号时,表明存在条从”到”的增广路,则转向增流过程(B)。如若”点不能被标号,且不存在其它可以标号的顶点时,表明不存在从”到”的增广路,算法结束,此时所获得的流就是最大流。
- (B)增流过程
- (1)
- (2)
- (3)
现需要将城市s的石油通过管道运送到城
市t,中间有4个中转站$v_1,v_2,v_3和v_4$,城市与中转站的连接以及管道的容量如下图所示,求从城市s到城市t的最大流。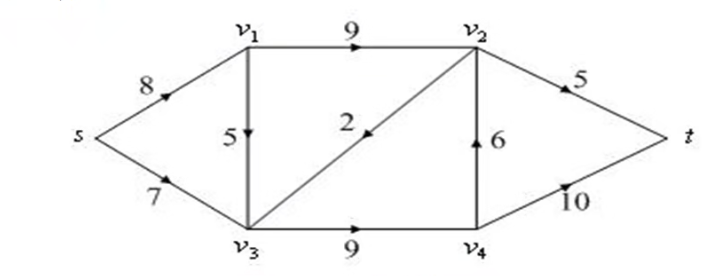
1 | model: |
在上面的程序中,采用了稀疏集的编写方法。下面介绍的程序编写方法是利用赋权邻
接矩阵,这样可以不使用稀疏集的编写方法,更便于推广到复杂网络。
1 | model: |
- 标题: 图与网络模型及方法
- 作者: rygdsddssd
- 创建于 : 2023-07-21 18:23:16
- 更新于 : 2023-11-01 15:51:09
- 链接: http://rygdsddssd.github.io/2023/07/21/图与网络模型及方法/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。